At the Staatsbibliothek zu Berlin, historical printed works are being processed so as to make them widely available to researchers. Knowledge itself thus becomes accessible. An interview with Clemens Neudecker.
Mr. Neudecker, you are in charge of several research projects at the Staatsbibliothek zu Berlin (Berlin State Library) that involve digitizing documents and then evaluating them. What is your impression: is digitization progressing even faster at the Staatsbibliothek as a result of the Corona pandemic?
Clemens Neudecker: Naturally. Because the reading rooms are closed, the demand for digitized documents, books, and manuscripts is increasing. This doesn’t mean that yesterday’s newspaper and the current best-selling books are going to be offered in digital form in libraries, either now or in the future. This is a disappointment to many visitors. The reason is copyright law, which is very strict. It is primarily the historical holdings that are being digitized – but they aren’t only of interest to professional researchers. We run labs, workshops and hackathons with a playful approach as a means of developing new programs and apps that will facilitate the creative use of historical documents. Even before Covid-19, we saw that our various digital services were generating more hits than our catalog – a trend that is sure to get stronger. However, digitization cannot replace access to the originals, it can only supplement it.
The Staatsbibliothek has its own large digitization center. Is there ever a break in the work?
Hardly ever. We scan around 1.7 million pages a year with special, very different devices in a two-shift system. That is remarkable – but given that we have at least 3 billion pages of books, we are just at the start. The scans are archived and imported into the digitized collections of the Staatsbibliothek. Most documents, however, are only available as images. Only around 15 percent of them have undergone text recognition, which is a process that converts the image into a searchable text using computer algorithms. So there is still plenty of work ahead. Developing suitable technologies for this is an essential part of my research work.
Why isn’t it enough just to take pictures of book pages?
Just scanning does allow them to be accessed digitally, but not to be searched for terms and certainly not browsed, in the sense that we understand it from Google, for example. For that, we need text recognition. Then the user can simply enter a term in a search mask and find the relevant passages of text, not just in one but in all of the documents digitized by the Staatsbibliothek – at least, if it works out as planned. Unfortunately, in the past, the technology required for this – OCR, or Optical Character Recognition – was not well suited to use with historical printed works. This has to do with the old German Fraktur font and the complex layouts of historical printed works. The resulting digital texts contained many errors of recognition. In the meantime, however, advances have been made in OCR technology. We now have new methods at our disposal, which we hope will soon enable us to produce error-free text scans of historical printed works. We are tackling this challenge in the OCR-D project, which is funded by the DFG and for which the Herzog August Library in Wolfenbüttel, the Berlin-Brandenburg Academy of Sciences and Humanities, the Karlsruhe Institute of Technology and the Staatsbibliothek zu Berlin have joined forces.
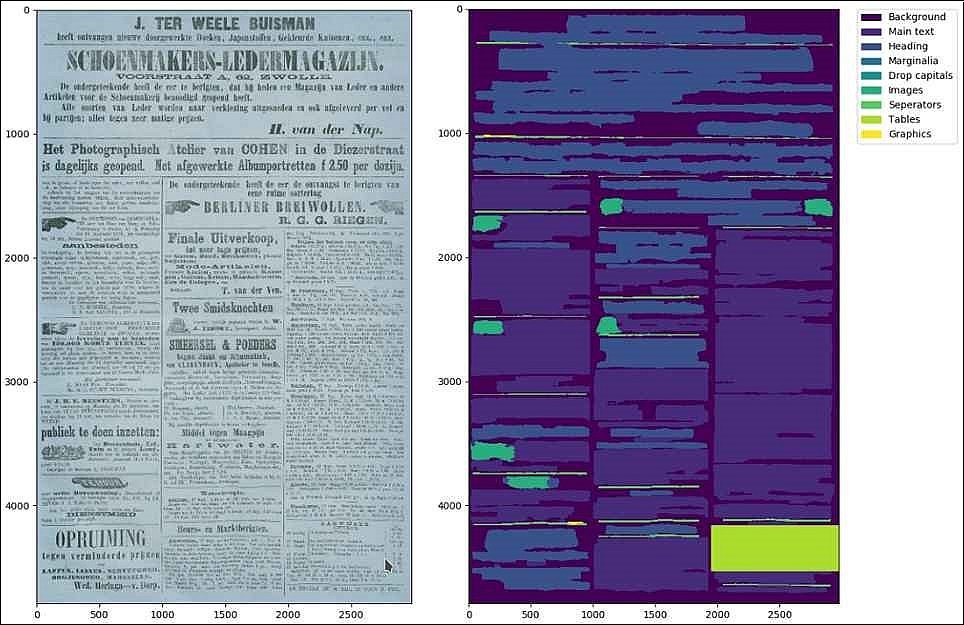


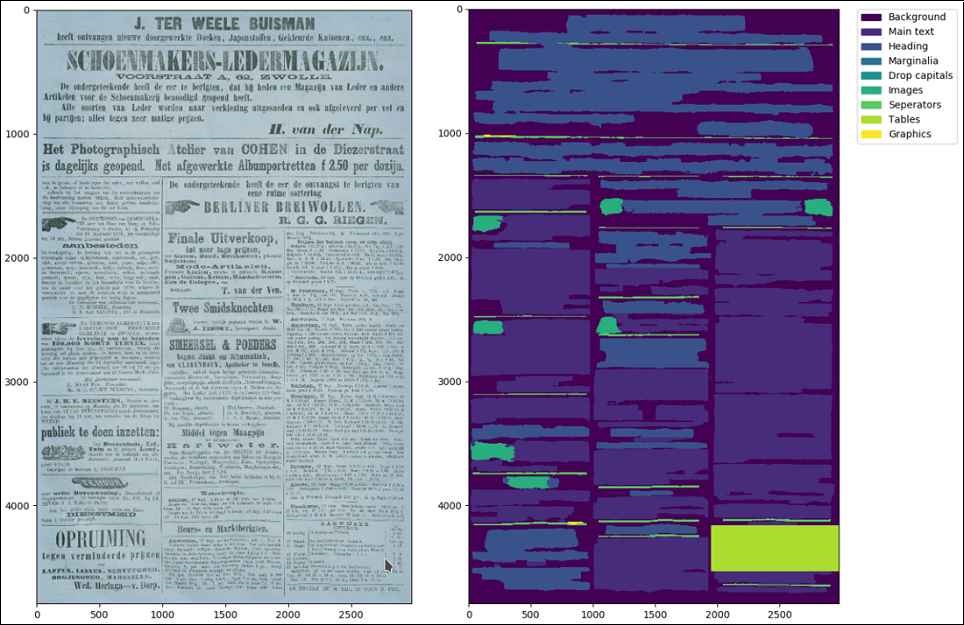
How exactly does OCR work?
OCR is a complex process. It is made up of a large number of separate steps, each with its own challenges, and each step depends on another. To begin with, there is the image optimization: the page margins are removed from the image, double pages are separated, and color illustrations, for example, are converted into black-and-white ones. Then comes what is known as segmentation, which involves identifying the paragraphs on a page, as well as the lines, tables, illustrations, and so on. After that, the program starts to recognize the words and letters.
So as not to mistake an “A” for an “O” ...?
Or a big “I” for a little one – that’s right. Then comes the quality assurance. Finally, the results may need to be corrected. It is crucial to find the best possible combination of all these processes for each specific digitized document.
What is the most difficult aspect of it for you?
The quality of the text that is created is paramount. Scientific users, in particular, need texts that are virtually free of errors for their research. The historical spellings from the printed original must be retained. In this respect, things are getting better and better, thanks to close collaboration between the OCR community and the libraries. It is important, however, that the program not only recognizes the words, but also the structure of the content. That means: Which part is a headline? Which part is a footnote? Where does a new paragraph begin? More development work needs to be done here, especially in respect of historical newspapers.
Links for Additional Information
And who will benefit most from all of this?
OCR makes knowledge accessible to everyone. Researchers in the digital humanities, in particular, have an interest in making texts fully available. I’ll give you an example: in the Oceanic Exchanges research project, we are working with scholars from Germany, the Netherlands, Finland, Great Britain, Mexico, and the USA, to study how news was spread in Europe and America during the nineteenth century. We are doing this on the basis of a transnational, digital inventory of well over 200 million digitized newspaper pages from various digital libraries. The results are fascinating. It makes a whole new dimension of research possible. A computer program determines the relevant text passages from millions of newspaper pages, and it does so in several languages. You can also run statistical or linguistic analyses this way: how often was a certain topic addressed in the nineteenth century, which terms were used in doing so, and how have these terms changed over time?
Are these works then made public? Who has access to the documents that you digitize?
The digitized works are generally available to the entire public, around the world and around the clock. By now, the digitized collections of the Staatsbibliothek also have the technical interfaces that are necessary for interested parties from all over the world to retrieve and work with the digitized documents automatically. The Staatsbibliothek pursues a comparatively open licensing policy in this case, under which the majority of the digitized historical works are made available in the public domain – or to be more precise, under a public domain license. We deviate from this only in special cases. Digitized documents from the twentieth century, in contrast, are often still restricted by copyright protection and suchlike. But in that area we only offer a few items.
The whole subject is very exciting. How did you end up working on it?
I have been familiar with OCR since my student days. Back then, I helped two blind fellow students: I scanned their literature for the semester and processed it with OCR software at a workstation that had been specially set up for the blind. That allowed the two of them to read the text on a refreshable Braille display or have it read aloud by a text-to-speech program. During my studies, I got a job at the digitization center of the Bavarian State Library, to do with evaluating OCR for digitization and designing an OCR workflow. Afterwards, I moved to the National Library of the Netherlands to take on the technical management of a large EU-funded project on OCR. At the time, people were still searching for a breakthrough in the new technology. Things will certainly be different on the current research project. We already have the first positive results. Never before have librarians and computer scientists, practice and research, worked so closely together. That continues to inspire me.