Clemens Neudecker ist in der Staatsbibliothek zu Berlin zuständig für Forschungsprojekte zur Datenanalyse mit Methoden aus den Bereichen Computer Vision, Natural Language Processing und Artificial Intelligence/Machine Learning. Neben der Forschung zu Methoden für die automatische Erschließung und Analyse von digitalisierten Beständen gilt sein Interesse auch der Zeitungsdigitalisierung sowie den Digital Humanities. Hier verrät er, ob Künstliche Intelligenz vielleicht bald seinen Job übernimmt
Was sind die Schwierigkeiten bei der automatischen Texterkennung im Zuge der Digitalisierung der Bestände?
Clemens Neudecker: Auch wenn bei der automatischen Texterkennung (Optical Character Recognition, OCR) durch technologische Fortschritte in den letzten Jahren inzwischen viele bekannte Probleme der Vergangenheit angehören – so ist es z.B. nun möglich, Frakturschriften und sogar Handschriften beinahe fehlerfrei mit einer Texterkennung zu verarbeiten – gibt es immer noch genügend Herausforderungen für die Texterkennung, die sich aus über vier Jahrhunderten Druckgeschichte und den vielfältigen Beständen ergeben und auch noch weitere Forschungsprojekte und Entwicklungen erfordern.
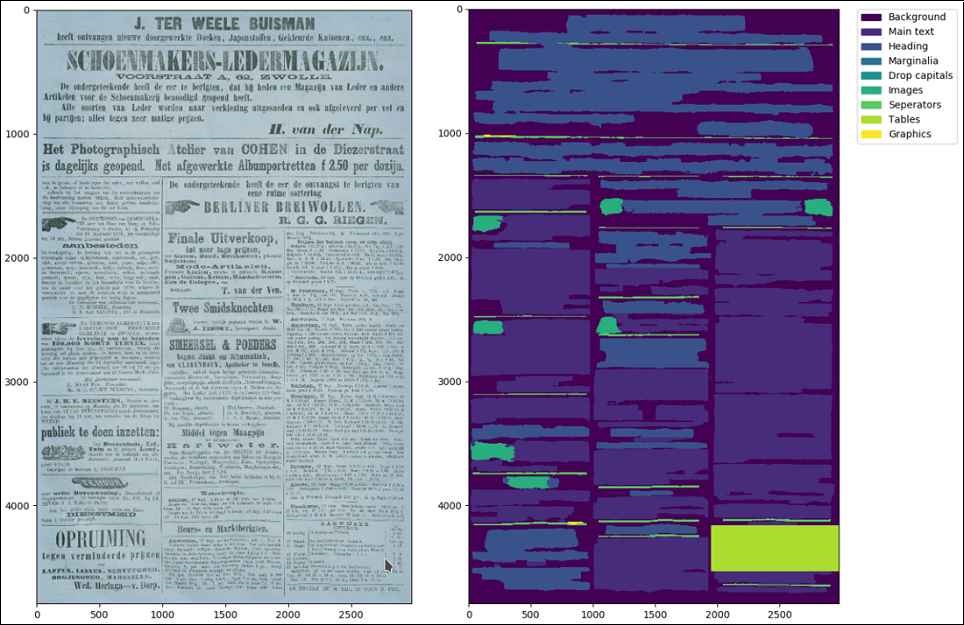
Die größte Schwierigkeit ist derzeit die Layoutanalyse (oder auch Segmentierung) der Dokumente, d.h. die Erkennung und Unterteilung unterschiedlicher Bereiche auf einer Seite wie Absätze, Überschriften, Fußnoten, Tabellen, Abbildungen etc. Eine weitere Schwierigkeit stellt die skalierbare Qualitätssicherung dar – im wissenschaftlichen Kontext wird hier „Ground Truth“, also die 100% korrekte Transkription, zu einem Vergleich mit der OCR herangezogen. Dies ist aber bei Millionen von Seiten nicht sinnvoll machbar, also müssen hierfür andere Methoden und Metriken entwickelt werden. An all diesen Themen arbeiten wir aktuell im DFG-Projekt OCR-D.
Welches ist das spannendste Forschungsprojekt, an dem Sie gerade arbeiten?
Clemens Neudecker: Das spannendste Forschungsprojekt ist für mich aktuell das von der Beauftragten der Bundesregierung für Kultur und Medien geförderte dreijährige Projekt „Mensch.Maschine.Kultur“. Hier geht es seit Mitte 2022 darum, die Erfahrungen aus Forschungsprojekten wie bspw. Qurator auszubauen, zu erweitern und – was bei derlei schnell voranschreitenden Bereichen wie der KI auch notwendig ist – zu aktualisieren, denn es hat sich hier in den letzten drei Jahren schon wieder viel getan. Außerdem geht es in diesem Projekt auch darum, die bisher in Forschungsprojekten entstandenen Prototypen in Zusammenarbeit mit unseren Abteilungen, aber auch Kund*innen aus der Wissenschaft, wie bspw. den Digital Humanities, zu konkreten Produkten und Diensten für die SBB weiterzuentwickeln.
Ein Aspekt der mich an dem Projekt besonders freut, ist, dass es auch gelungen ist, eines von insgesamt vier Teilprojekten der wichtigen Frage zu widmen, wie Kultureinrichtungen wie Bibliotheken, Museen und Archive, die durch die Digitalisierung über große Mengen an Daten verfügen, diese für die Verbesserung von KI nutzbar machen können – und zwar mit dem bei kommerziellen KI oft vernachlässigten Anspruch, dies auf eine Art und Weise zu tun, die potentiellen ethischen, sozialen und rechtlichen Problemen der Daten und KI transparent und im Austausch mit der wissenschaftlichen Community begegnet.
Übernimmt die KI irgendwann Ihren Job?
Clemens Neudecker: Manchmal würde ich mir das schon wünschen, ich selbst glaube aber nicht daran, dass dies in naher oder gar ferner Zukunft eintreten wird, auch nicht bei solchen Aufgaben in der Bibliothek, wie wir sie aktuell zumindest teilweise versuchen zu automatisieren. Letztendlich muss man sehen, dass KI im Sprachgebrauch außerhalb der Informatik oft ein schwammiger und durchaus problematischer Begriff ist, wir selbst sprechen daher lieber von „Maschinellem Lernen“.
Darin drückt sich besser aus, dass wir keine Intelligenz in einem mit dem Menschen vergleichbaren Sinn entwickeln, sondern vielmehr versuchen, einer Maschine beizubringen, etwas automatisch zu tun, indem wir ihr viele Beispiele zeigen – also die Maschine dafür „trainieren“ eine recht spezifische Aufgabe zu erledigen. Dafür braucht es mehr denn je menschliche Expert*innen, die zwar der Maschine etwas beibringen, diese aber dann auch immer wieder bei Fehlern korrigieren können.